Abstract
Relational databases are difficult to split apart over clusters of servers. NoSQL databases offer businesses a data storage/retrieval system for processing large amounts of transactions online. Businesses conduct more transactions online than ever before, and the data involved is only expected to keep growing with increased traffic. NoSQL arose as a solution to the impedance mismatch problem between relational data models and object-oriented data models. NoSQL encompasses four different data organization models which are highly-customizable to businesses based on their needs. The main advantage of using NoSQL is that they access large amounts of data across clusters quickly. A NoSQL database is flexible, scalable, and easy to design and implement. NoSQL can sacrifice consistency for accessibility, however. Businesses should know their specific needs for a data model to help them choose which will be right for their needs. A business can have multiple databases to cover a variety of needs.
Keywords: NoSQL, object-relational, RDBMS, CAP Theorem (Consistency, Accessibility, Partition Tolerance), ACID (Atomic, Consistency, Isolation, Durability), BASE (Basically Available, Soft-state, Eventual consistency)
Introduction
Every search on Google or order from Amazon utilizes a NoSQL database. NoSQL databases cannot be defined, but most of them have common characteristics. At a GOTO conference (2013) in Denmark, Fowler states that the name “#nosql” was a Twitter hash tag to advertise and coordinate the initial brainstorming meeting among database developers to work on solving the issue of being able to split a database across multiple servers (nodes) for processing big data. Another issue that gave rise to the need for the NoSQL data model was impedance mismatch between object-oriented technologies and traditional relational technologies. Impedance mismatch happens because object oriented programming principles require what is called “data encapsulation” – an object’s function should be separate from its representation. The function (what can be done with an object) should be separate from its representation (the data of which an object is made). With RDBMS, the data is defined by type (string or integer), whereas with object oriented, the types and structure of the data define the function. From an object oriented perspective, an object should not be defined by the data, but be defined independently of it and make use of that data. The problems arise when objects use databases for storing data, and then the objects and properties change or evolve over time.
Relational databases, procedural, rigid, and structured with an entity relationship diagram, are difficult to break apart into smaller pieces (“sharded”) and become unwieldy when used in a cloud environment. With the traditional RDBMS model, in order to handle big data traffic, the server has to be exponentially more powerful to handle the server requests (and thus unfeasibly expensive), or else split across multiple, smaller servers (difficult to implement with RDBMS). NoSQL’s more “object friendly” data model provided for better splitting computing across multiple clusters of computers (particularly if they are far apart, which RDBMS can not do at all), as well as encapsulating data within each “object” so that the underlying content is not exposed. For businesses that process huge numbers of transactions (which is what NoSQL was mainly formulated to handle), speed and accessibility trump reliability and consistency. The goal of speed and accessibility is to have the page available quickly, even if it is not 100% accurate. The average attention span of someone surfing the web is now measured in nanoseconds, and if a web request does not produce a visible result within at least a second, the user will navigate away, assuming something is wrong.
“Non-relational” is often assigned to this loose group of storage/retrieval data models. Meijer and Bierman (2011) propose “coSQL” as a new name for the most common NoSQL “key/value” data model, citing the mathematical relationship between key/value stores and the foreign key/primary key stores of traditional, relational SQL databases. Key/Value is only one model of four, however, and in the three aggregate data models, implicit relationships exist, and records are still accessed by their respective “key,” just as with relational databases, albeit a chunk of data together, rather than data split into its smallest parts. Relational databases are not in danger of being replaced by NoSQL, however. In a recent survey by Tesora of 500 North American “new technology” companies, 79% used relational databases while only 16% used some form of NoSQL, with MongoDB and Hadoop accounting for 10% and 8% of those, respectively (Yegulalp, 2014). While that may be the case now, NoSQL databases will continue to become more prevalent in business use, particularly on the web. Because NoSQL is an emerging technology, more people must be trained in its use and implementation before it can gain more ground in the business world. Relational databases will still be the best business solution for many businesses, as the data model chosen will depend on a businesses’ needs. However, with a large business with huge data sets and transactions that that the data is distributed across clusters that are far apart, a relational model will not work. NoSQL databases offer a cost-effective, scalable, and flexible solution for business handling processing transaction requests involving huge amounts of data quickly, if not always as reliable or consistent as traditional databases.
Common Characteristics of Most NoSQL Databases
NoSQL databases are mostly open-source, making them more affordable than proprietary or commercial “enterprise” databases that are also scalable, such as Oracle and Microsoft SQL Server, both object-relational databases (ORDBMS). While MySQL and PostgreSQL are also open-source and scalable, as well as fast for small data sets, they would not perform as quickly across clusters of servers as NoSQL. NoSQL is cluster-friendly, making it easily scalable, as large data sets can easily be split across clusters, with or without replication, to store their respective “part” of the whole, in respective data objects. Being schema-less, content can be looser, more flexible, not constrained to specific fields as in relational models, but rather groupings of data in each object. For instance, Amazon uses Dynamo, a high performance, key/value NoSQL database for its online transactions, for which they guarantee a specific turn-around-time (in milliseconds) for requests, combining hundreds of services that work together, ranging from making recommendations (based on past purchases or even searches), order processing and fulfillment, as well as fraud detection, with reduced latency and guaranteeing efficiency and reliability. This guarantee comes from Amazon’s (2007) Service Level Agreements (SLA) between client and service, a contract which guarantees “to provide a response within 300ms for 99.9% of its requests for a peak client load of 500 requests per second” (p. 207). Figure 1, below, shows an abstract of how these client requests are routed, aggregated, and served.
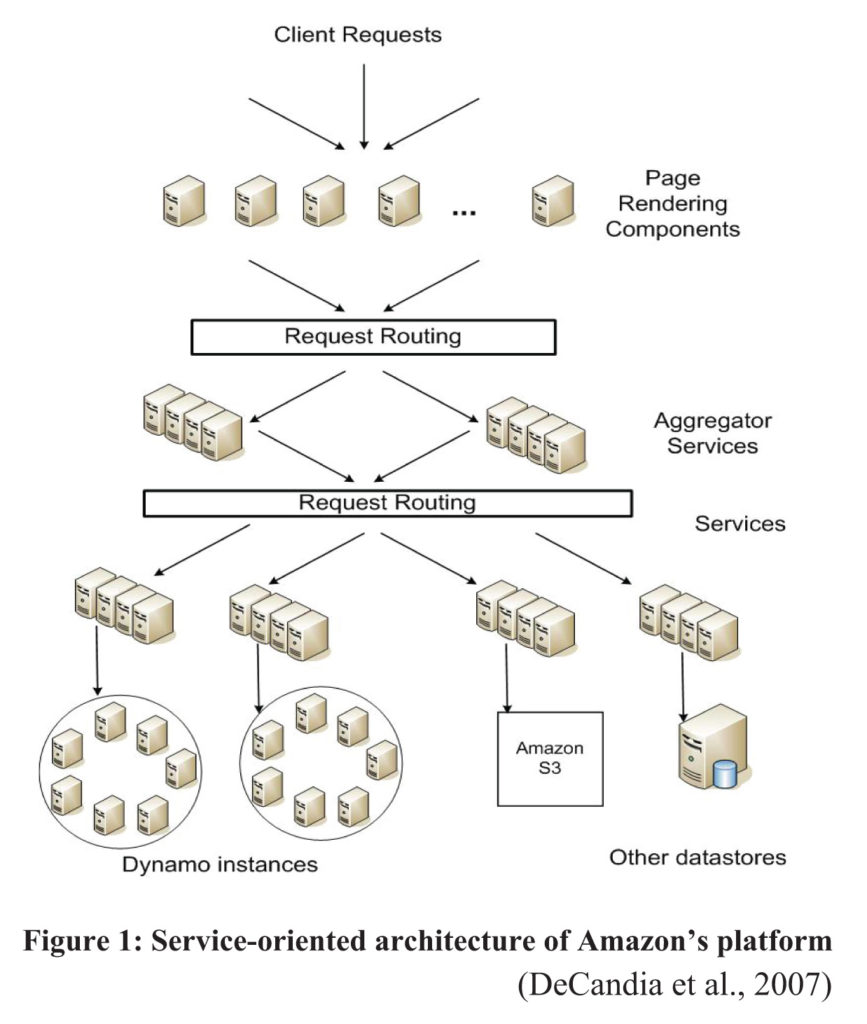
It is clear from Amazon’s SLA promise for Dynamo, as well as this diagram, the value that cluster-computing and aggregation play in delivering high performance speed as well as reliability, using a key/value NoSQL data model.
Four Data Models of NoSQL Databases
- Key/Value store (Key fetches associated object, which sometimes has metadata with indexes)
- Document (Data is usually stored in JSON, and schema is implicit through use of id’s)
- Column Family (Row key with column families—more complex aggregate data model)
- Graph-Database (The only non-aggregate NoSQL data model)
The first three data models listed above are aggregate, having something in common with relational databases in that they have some sort of key or id that accesses associative blocks of data (the “aggregate”). The graph model of NoSQL database is organized quite differently, without a clear hierarchy. Instead, as illustrated below in Figure 2, the data structure is based on relationships of the data to itself, forming loose groupings according to nodes and arcs defined in the database design. Though loosely “relational,” the graph model bears little resemblance to traditional relational database models, being completely schema-less.
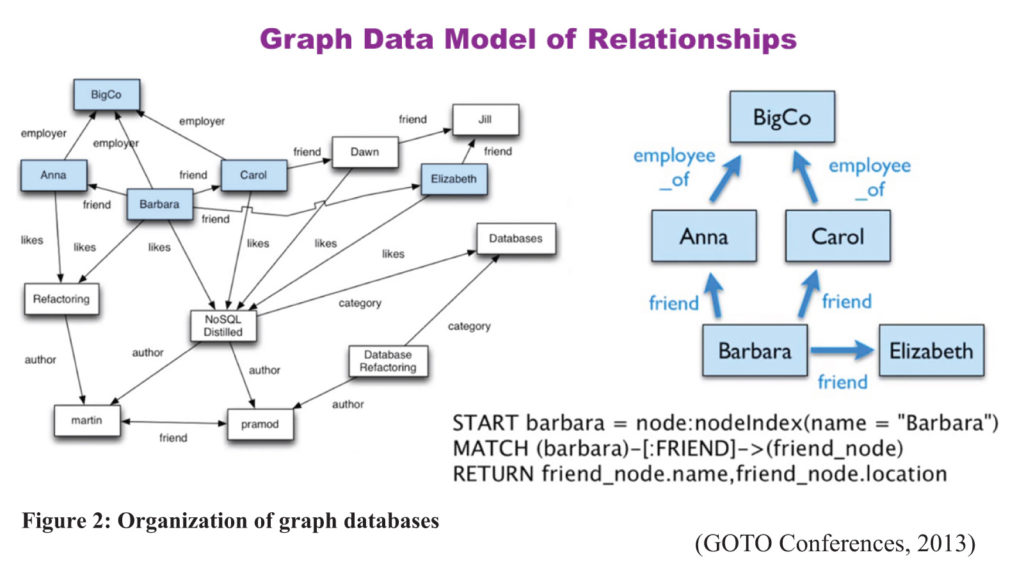
With a looser data structure than RDBMS, it is easy to scale NoSQL databases by simply adding or removing aggregates or nodes. The flexibility of NoSQL comes from the ability to add or subtract data to or from existing aggregates or nodes. Organizing by aggregates makes for easier development and implementation, particularly across clusters of servers, potentially spread around the world.
Whereas relational models split data into its smallest components, NoSQL assembles the data into aggregates or nodes, which can be tailored, to the business’s specific data needs. Figure 3, below, provides an illustration of the configurability of NoSQL versus RDBMS data models. This example also illustrates how the NoSQL model achieves speed, as the data being accessed is already assembled, whereas with RDBMS, the individual pieces come split apart and need to be aggregated as the result of each query or transaction.

Defining Business Needs
Knowing how data is handled is integral to understanding which data model to choose. How does the business work with its data? Does it tend to work with the same aggregates? If so, then key/value or document model would be appropriate solutions. Is their goal to break up data and jump across it in a complicated relationship structure? In that case, graph could be the answer, as it optimizes finding relationships. Alternatively, if a tabular structure is what is needed, a column data model could be used. With column databases, it is easier to pull out pieces of data, rather than the whole aggregate, as well as distribute data across different nodes in clusters by aggregate orientation.
CAP-Theorum
Any business using a NoSQL data model spread out over a wide area has to choose two out of three characteristics: Consistency, Availability, and Partition Tolerance, as it is mathematically impossible to have all three. “Partition” means “in pieces” and so a partitioned network means you have two parts of the system that are both “up” but not connected anymore. If that happens, then either the two partitions can’t talk to each other and that’s okay if they give different results (inconsistency) or the particular piece of data the user requests isn’t available to be read or written to (not reliable). Often businesses will choose availability and partition tolerance over consistency, and this decision impacts how the data system is designed, such as building in redundancy by distribution over multiple nodes to ensure availability. In a video posted on YouTube by GOTO (2013), Martin Fowler stated the following:
If you’ve got a system that can get a network partition, which basically means communication between different nodes in a cluster breaking down (and if you have a distributed system, by the way, you are going to get network partitions). If you have a system that has a network partition, you have a choice–do you want to be consistent, or do you want to be available?
Most businesses would prefer to have their transactions available than consistent to avoid having down time, as down time may lose a sale. It is also possible to design a spectrum between the two, for instance more consistency for less availability, and vice versa. This spectrum of functionality can also be split between different types of operations, with some being more consistent, some more available, depending on their purpose. Often the trade-off is consistency for response time, not availability alone. The data may be available, but not immediately, therefore response time is important for holding the user’s attention.
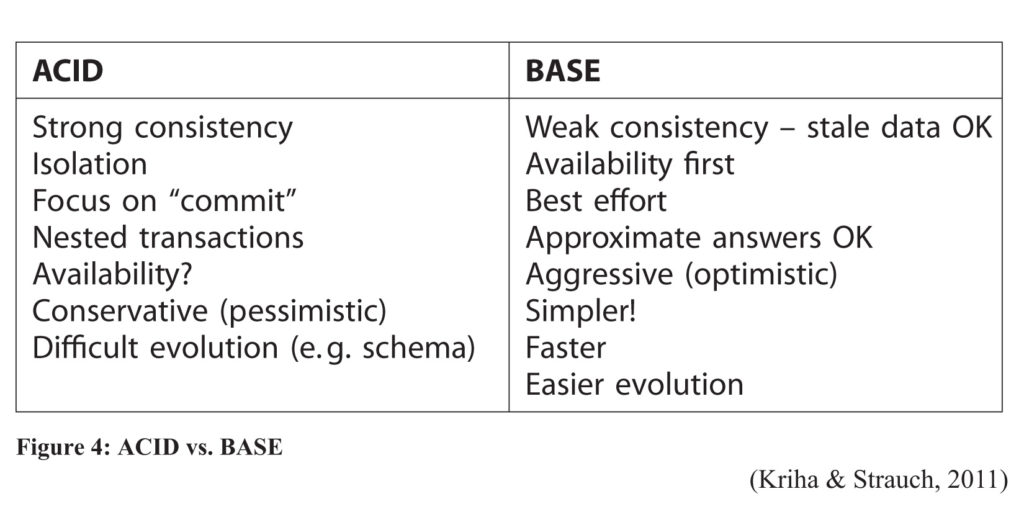
ACID vs. BASE
ACID (Atomic, Consistency, Isolation, Durability) describes characteristics common to relational databases, whereas BASE (Basically Available, Soft-state, Eventual consistency) is the approach that most NoSQL models take, forfeiting consistency and isolation in favor of availability and performance. Similar to the CAP theorem, these attributes can be applied in a spectrum between the two, rather than strictly either one. For instance, NoSQL aggregate-oriented databases deal mainly with transactions, keeping each transaction within aggregate boundaries. Therefore they are ACID with their respective aggregates. (Atomic means consistent overall updates.) Troubles may arise if multiple people are trying to update the same data at the same time. One way to forestall this is to use an auto-increment version stamp on each update and create a transaction boundary around that update.
Challenges of NoSQL
New Technology. NoSQL is a relatively new technology and therefore many businesses are leery of implementing it. NoSQL has several challenges: immaturity, lack of support and expertise, as well as not being friendly to analytics. Enterprises like stability and reliability, preferring mature solutions such as an RDBMS provides. Maturity in technology is important to businesses because it proves it can stand the test of time, is dependable and stable, having certain standards. NoSQL is a new technology, so while it is certainly “cutting edge,” it is not mature nor is it standardized, and businesses may not want to invest heavily in a technology that may not endure. Stonebraker (2011) argues that “NoSQL means no standards…Seemingly, there are north of 50 NoSQL engines, each with a different user interface. Most have a data model, which is unique to that system, along with a one-off, record-at-a-time user interface” (p. 10-11). Standards are especially important to large enterprises using multiple databases, because of variety of interfaces their application programmers have to learn. Therefore, tasking them to adopt a new technology with loose standards can be a burden and slow down business during the implementation phase, as well as make maintenance initially more difficult.
Support. Another issue with NoSQL is lack of credible support, since NoSQL is open-source, and the few firms that offer support for NoSQL databases are often small startups without the global reach and resources of the larger, established companies, such Oracle, Microsoft, and IBM. More people need to be trained to implement and maintain NoSQL databases before NoSQL can be competitive with RDBMS. Few experts in NoSQL exist, and the majority of developers are in the discovery and learning phase, whereas RDBMS has millions of developers globally. As NoSQL gains more maturity however, developers will become more familiar with it and the pool of experienced NoSQL experts will grow.
Analytics. Another important consideration for businesses is data analytics on product performance or sales trends over time. In the YouTube video by GOTO (2013), Fowler illustrates that with the NoSQL model, analytics are difficult to extrapolate, whereas in a relational database model, such queries around business trends are quite normal and easy to execute. However, according to Harrison (2010), “Some relief is provided by the emergence of solutions such as HIVE or PIB, which can provide easier access to data held in Hadoop clusters and perhaps eventually, other NoSQL databases. Quest Software has developed a product – Toad for Cloud Databases – that can provide ad-hoc query capabilities to a variety of NoSQL databases.” (Analytics and Business Intelligence section, para. 3). In response to the need for analytics, therefore, solutions are being developed, which will continue to add some of RDBMS’s rich functionality to NoSQL. Business should consider what they need most from their data storage and retrieval system and choose what system is best for their needs, as each system has its strengths and limitations. The main advantage of NoSQL remains its ability to handle big data sets in the cloud with great speed and accessibility, which is not what every business needs. It is up to each business to determine priorities with how it chooses to handle data, and choose a system accordingly.
Conclusion
Large-scale data is a fact of life for businesses today. While NoSQL provides several viable solutions to handling big data, they will not replace relational databases, but rather add to them. Each data model has its particular use, and businesses will benefit from choosing the type of database suited to the nature of the problem they are trying to solve, keeping in mind that they can have multiple types of databases in use in any one organization. Relational databases are familiar, and can be used for utility projects, whereas NoSQL is an immature technology–very new, so not many people know how to work with it, but it may be worth the risk for a business to use NoSQL if they are implementing something strategic that needs to handle big data or have fast access for a competitive advantage (such as with Amazon).
The subject of NoSQL databases is huge, and consequently, this report did not go into issues such as security (as SQL injection is an issue with NoSQL as well as with SQL databases), vector clocks, or sharding. While it is mathematically impossible for all three of the CAP theorem to be implemented, researchers may find strategies to mitigate or minimize problems with availability or consistency in the presence of a network partition, which could result in NoSQL rising in popularity. NoSQL could also be eclipsed by PostgreSQL, which incorporates much of the functionality of NoSQL, is fast with large data sets on a single server, uses JSON as its architecture, and is open-source with one company (Enterprise DB) offering firm support.
Necessity breeds invention. In order for businesses to deal with big data across the internet, they need a system which provides high scalability, ability to process large amounts of data, distribute that data among many (commodity) servers as well as provide integration with programming languages and an interface to interact with that data. NoSQL, even with the limitations of consistency, has shown to be the data model that has risen to meet that need.
References
Chaudhri, A. (Director) (2013, May 7). Considerations for using NoSQL technology on your next IT project. The Skills Matter eXchange. Lecture conducted from London Java Community, London, UK. Retrieved from https://skillsmatter.com/skillscasts/4146-considerations-for-using-nosql-technology-on-your-next-it-project
DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A., Sivasubramanian,, S., Vosshall, P., Vogels, W. (2007, September 1). Dynamo: Amazon’s Highly Available Key-value Store. Retrieved November 4, 2014, from http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
GOTO Conferences. (2013, February 18). Introduction to NoSQL by Martin Fowler [Video File]. Retrieved from https://www.youtube.com/watch?v=qI_g07C_Q5I
Gunter, D. (Director) (2011, June 1). NoSQL: “Huh? What is it good for?”. Cloud Computing Workshop. Lecture conducted from Computation Research Division, LBNL, Berkely, CA.
Harrison, G. (2010, August 26). 10 things you should know about NoSQL databases. Retrieved November 11, 2014, from http://www.techrepublic.com/blog/10-things/10-things-you-should-know-about-nosql-databases/
Kriha, W., & Strauch, C. (2011, February 5). NoSQL Databases. Retrieved October 25, 2014, from http://coitweb.uncc.edu/~xwu/5160/nosqldbs.pdf
MEIJER, E., & BIERMAN, G. (2011). A Co-Relational Model of Data for Large Shared Data Banks. Communications Of The ACM, 54(4), 49-58. doi:10.1145/1924421.1924436
Stonebraker on NoSQL and Enterprises. (2011). Communications of the ACM, 54(8), 10-11. doi:10.1145/1978542.1978565
Stonebraker, M. (2010). SQL Databases v. NoSQL Databases. Communications Of The ACM, 53(4), 10-11. doi:10.1145/1721654.1721659
Vinodray, P., Krishna, J., Dhinesh Babu, L. D., & Nagnath, B. (2013). Deploying Scalable Car Reservation System Based on Cloud Using Google App Engine. International Journal Of Applied Engineering Research, 8(19), 2534-2438.
Wambler, S. (2014, July 24). The Object-Relational Impedance Mismatch. Retrieved October 23, 2014, from http://www.agiledata.org/essays/impedanceMismatch.html
Yegulalp, S. (2014, June 18). Not so fast, NoSQL — SQL still reigns. Retrieved November 2, 2014, from http://www.infoworld.com/article/2607910/database/not-so-fast–nosql—-sql-still-reigns.html